大数据存储与处理 Hive与Pig的数据处理与存储服务探析
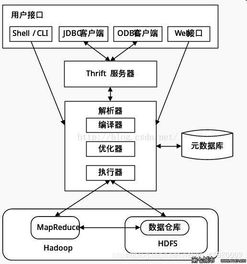
随着大数据技术的飞速发展,Hive与Pig作为Hadoop生态系统中的重要组件,为海量数据的存储与处理提供了高效、可扩展的解决方案。本文将从数据处理和存储服务的角度,深入探讨Hive与Pig的核心功能、应用场景及其互补关系。
1. Hive:基于SQL的数据仓库工具
Hive是一个构建在Hadoop之上的数据仓库工具,它允许用户使用类似于SQL的HiveQL语言来查询和管理存储在HDFS(Hadoop分布式文件系统)中的大规模数据集。其主要特点包括:
- 数据存储:Hive将数据以表的形式组织,支持结构化数据的存储,数据实际存储在HDFS中,元数据则保存在关系型数据库(如MySQL)中。
- 数据处理:通过HiveQL,用户可以执行数据查询、聚合、过滤等操作,Hive会自动将查询转换为MapReduce任务在Hadoop集群上执行。
- 适用场景:适用于离线批处理、数据仓库构建、历史数据分析等需要复杂查询和聚合的场景。
2. Pig:数据流处理平台
Pig是一个用于大规模数据分析的平台,它提供了一种名为Pig Latin的高级脚本语言,专注于数据流的处理。其核心优势在于:
- 数据模型:Pig基于嵌套数据模型,支持复杂数据类型(如Map、Tuple、Bag),更适合处理半结构化或非结构化数据。
- 数据处理流程:Pig Latin脚本描述了数据从加载、转换到存储的完整流程,Pig会将其编译为一系列MapReduce任务执行。
- 适用场景:适用于ETL(提取、转换、加载)任务、数据流水线处理、迭代计算等需要灵活数据处理的场景。
3. Hive与Pig的互补性
尽管Hive和Pig都服务于大数据处理,但它们在设计哲学和应用层面各有侧重:
- 语言差异:Hive采用类SQL的声明式语言,更适合熟悉SQL的数据分析师;Pig使用过程式的脚本语言,更适合描述复杂的数据流水线。
- 性能特点:Hive在复杂查询和聚合操作上优化较好;Pig在数据流水线和多步转换任务中表现更高效。
- 协作使用:在实际项目中,Hive常用于构建数据仓库和即席查询,而Pig用于数据清洗和预处理,两者可以协同工作,提升整体数据处理效率。
4. 存储与处理的集成服务
在大数据架构中,Hive和Pig通常与HDFS、YARN等组件紧密集成,形成完整的数据处理与存储服务链:
- 存储层:HDFS提供高容错、高吞吐量的分布式存储,为Hive表和Pig数据源提供底层支持。
- 资源管理:YARN负责集群资源调度,确保Hive和Pig任务高效执行。
- 数据交互:Hive和Pig可以共享HDFS中的数据,并通过HCatalog等工具实现元数据互通,简化数据管理流程。
5. 与展望
Hive和Pig作为大数据处理的关键工具,分别从声明式查询和数据流处理的角度,降低了大规模数据处理的复杂度。随着云计算和实时处理技术的发展,Hive on Spark、Pig on Tez等新架构进一步提升了处理性能。它们将继续与新兴技术融合,为企业在数据存储、处理与分析方面提供更强大的服务支持。
最新产品
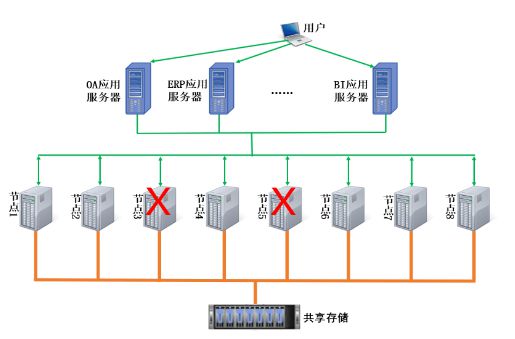
优炫软件在DTCC发布共享存储多写多读集群数据库,引领数据处理与存储服务新浪潮
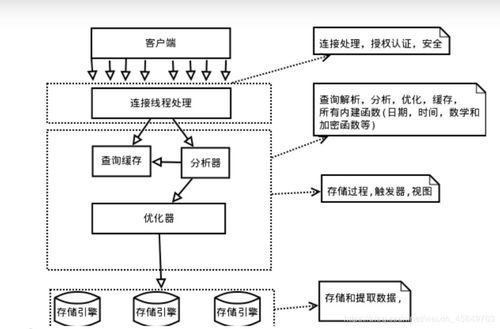
MySQL数据库 核心特点、架构解析与Linux环境实践
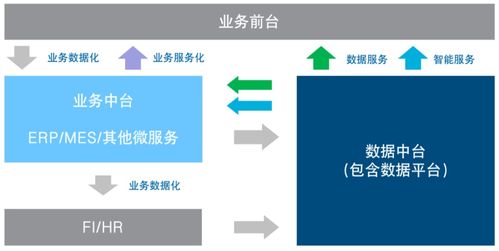
ERP的未来架构 数据处理与存储服务的革命性演进
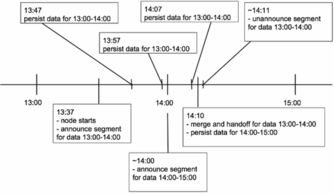
Druid 大数据实时统计分析与数据处理存储服务
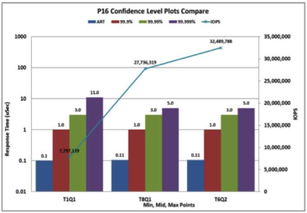
Calypso Systems推出测试软件与服务器,加速傲腾数据中心级持久内存数据处理与存储服务发展
大数据存储与处理 Hive与Pig的数据处理与存储服务探析
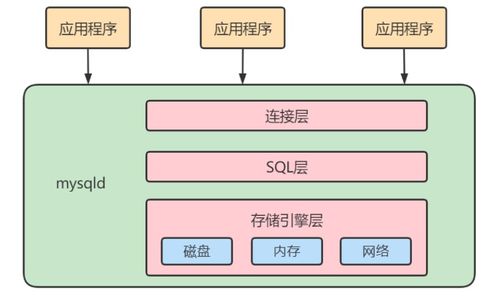
MySQL高级系列之一 深入解析数据处理与存储服务
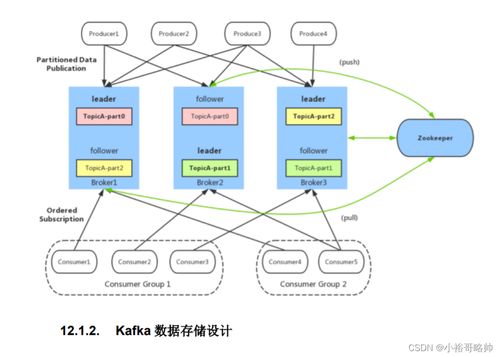
面试笔记系列六 Redis、Kafka、Zookeeper与MongoDB核心梳理及对比
从原理到实践 互联网大厂的分布式事务解决方案全解析
Oracle RAC上云实战指南 数据处理与存储服务的高效迁移与部署