Druid 大数据实时统计分析与数据处理存储服务
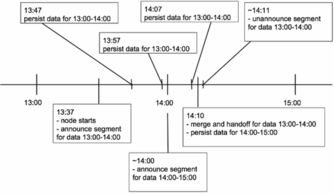
在当今数据驱动的时代,企业对数据的实时分析与处理能力提出了前所未有的高要求。Druid,作为一个开源的分布式列式数据存储系统,应运而生,专门为支持交互式查询和实时分析大规模数据集而设计。它能够高效地处理海量事件流数据,提供亚秒级的查询响应,使其成为大数据实时统计分析和数据处理存储服务领域的明星解决方案。
Druid的核心特性
Druid的设计哲学融合了数据仓库、时序数据库和搜索系统的优点,主要具备以下核心特性:
- 列式存储:Druid采用列式存储格式,这意味着查询时只需读取相关的列,而非整行数据,极大地提高了聚合查询和扫描的效率,尤其适合统计分析场景。
- 分布式架构:Druid天然是分布式的,可以轻松水平扩展以处理PB级别的数据。其架构通常包含协调节点、历史节点、代理节点等多个角色,各司其职,共同协作。
- 实时与批量数据摄入:Druid支持从流数据源(如Kafka、Kinesis)进行实时数据摄入,也支持从HDFS、S3等文件系统进行批量数据摄入。这种灵活性使得它能够构建统一的实时与历史数据分析平台。
- 亚秒级查询:通过其优化的数据格式、预聚合能力(Roll-up)和分布式查询引擎,Druid能够对数十亿行数据进行亚秒级的交互式查询,是构建实时仪表盘和监控系统的理想后端。
- 高可用性与容错性:数据在Druid集群中被复制和分片存储,确保在节点故障时服务不中断,数据不丢失。
作为数据处理与存储服务的角色
在一个完整的大数据技术栈中,Druid主要扮演着实时OLAP(在线分析处理)引擎和高性能数据存储服务的角色。
- 数据处理层面:数据从源头(如应用日志、物联网传感器、点击流)产生后,可以实时或批量地流入Druid。Druid会对其进行索引、预聚合(可选)和分区。预聚合是Druid的一个强大功能,它可以在数据摄入阶段对数据进行汇总,从而在查询时显著减少需要扫描的数据量,这是实现高性能查询的关键。
- 数据存储层面:处理后的数据以高度优化的、不可变的“段”(Segment)文件形式存储在深度存储(如HDFS、S3)中,并由历史节点加载到内存或本地磁盘以供查询。这种存储方式既保证了数据的持久性,又为快速查询提供了可能。
典型应用场景
Druid非常适合需要快速洞察海量事件数据的场景,例如:
- 实时业务监控与仪表盘:实时展示网站/APP的PV、UV、交易额、用户行为漏斗等关键指标。
- 网络性能监控:分析网络设备产生的海量日志和指标数据,实时定位问题。
- 广告技术分析:实时分析广告曝光、点击、转化数据,用于竞价优化和效果评估。
- 物联网数据分析:处理来自传感器的高频数据流,进行实时监控和趋势分析。
- 用户行为分析:对用户在产品内的点击、浏览、购买等行为进行实时多维分析。
技术栈中的定位
通常,Druid与以下技术协同工作:
- 数据摄入层:Apache Kafka(实时流)、Apache Flink/Spark Streaming(流处理),或直接使用Druid的原生摄取任务(批量)。
- 深度存储层:HDFS、Amazon S3、Google Cloud Storage等,用于持久化存储数据“段”。
- 元数据存储:通常使用MySQL或PostgreSQL存储集群的元数据信息。
- 查询与可视化层:通过Druid自带的JSON-over-HTTP查询API,可以被Apache Superset、Grafana、Tableau等可视化工具直接连接,也可以被应用程序直接调用。
###
Druid通过其独特的架构设计,在大数据实时统计分析领域找到了一个精准的生态位。它不是一个通用的关系型数据库,也不是一个原始的流处理引擎,而是一个专为“快速回答关于大量事件数据发生了什么”这个问题而优化的高性能、实时分析型数据存储与查询服务。对于需要从海量实时数据中即时获取业务洞察的企业来说,将Druid纳入其数据处理流水线,能够有效解决传统方案在查询延迟和系统扩展性上的瓶颈,赋能基于数据的实时决策。
最新产品
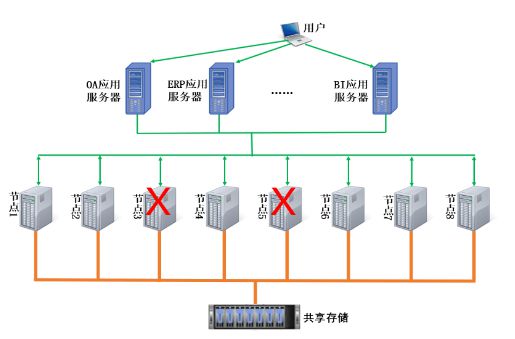
优炫软件在DTCC发布共享存储多写多读集群数据库,引领数据处理与存储服务新浪潮
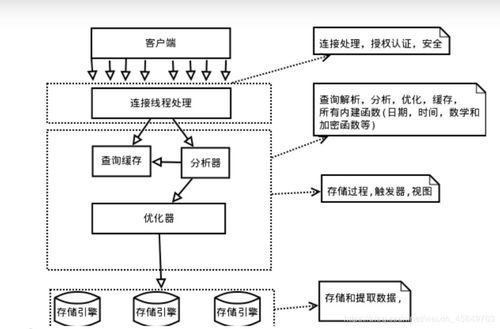
MySQL数据库 核心特点、架构解析与Linux环境实践
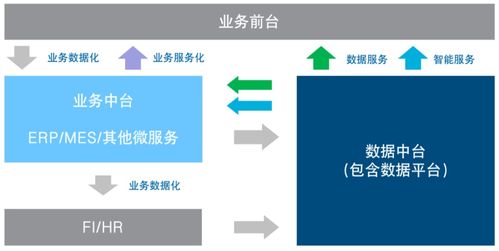
ERP的未来架构 数据处理与存储服务的革命性演进
Druid 大数据实时统计分析与数据处理存储服务
Calypso Systems推出测试软件与服务器,加速傲腾数据中心级持久内存数据处理与存储服务发展
大数据存储与处理 Hive与Pig的数据处理与存储服务探析
MySQL高级系列之一 深入解析数据处理与存储服务
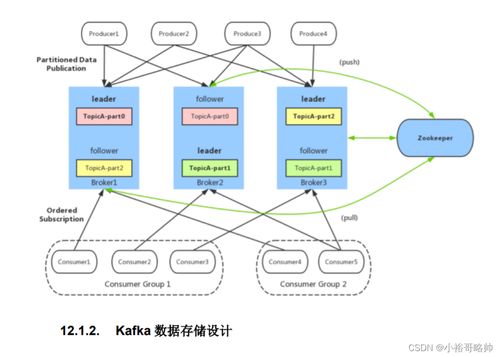
面试笔记系列六 Redis、Kafka、Zookeeper与MongoDB核心梳理及对比
从原理到实践 互联网大厂的分布式事务解决方案全解析
Oracle RAC上云实战指南 数据处理与存储服务的高效迁移与部署