当业务发展遇上分库分表 数据处理与存储服务的架构演进
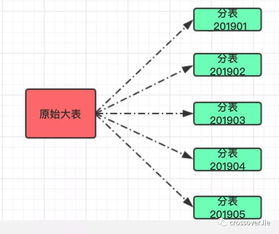
随着业务的快速增长,数据量的急剧膨胀往往会使单一数据库的处理能力触及瓶颈,系统响应变慢,维护成本剧增。这时,分库分表技术便成为系统架构演进中不可或缺的关键一步。它不仅是技术手段,更是业务发展到一定规模后,数据处理与存储服务必须面对的架构挑战与解决方案。
一、 为什么需要分库分表?
- 性能瓶颈:单库单表的数据量(如超过千万级)和访问量(高并发TPS/QPS)达到数据库软硬件上限,导致查询缓慢、写入超时。
- 存储瓶颈:单机磁盘容量无法满足海量数据(如日志、交易记录)的长期存储需求。
- 可用性与扩展性:单一数据库实例存在单点故障风险,且垂直升级(Scale-up)成本高昂、有上限。水平扩展(Scale-out)能力成为刚需。
- 业务隔离:不同业务模块(如用户、订单、商品)对数据库的要求各异,混在一起相互影响,需要通过分库实现业务解耦和资源隔离。
二、 分库分表的核心策略
分库分表本质上是将数据按照一定规则分散到多个数据库或数据表中,其核心策略可分为两类:
- 垂直拆分:
- 垂直分库:根据业务模块进行拆分。例如,将用户相关的表放在
用户库,订单相关的表放在订单库。这降低了单库压力,便于业务团队独立维护。
- 垂直分表:将一张宽表(包含过多字段)按访问频次或业务相关性拆分成多张表。例如,将用户基础信息(高频查询)和用户详情/扩展信息(低频查询)分开。
- 水平拆分:
- 水平分库:将同一个表的数据,按规则(如用户ID哈希、时间范围)分布到多个数据库实例中。每个库的表结构完全一致。
- 水平分表:将同一个表的数据,按规则分布到同一个数据库的多个物理表中。这是最常用的“分表”形式。
实际应用中,通常是垂直与水平拆分结合使用,形成复杂的分布式数据网络。
三、 数据处理与存储服务面临的挑战
引入分库分表后,数据处理与存储服务的复杂度呈指数级上升:
- SQL路由:应用系统如何知道一条查询应该发往哪个具体的库或表?这需要引入中间件(如ShardingSphere、MyCat)或客户端SDK来透明化地处理SQL解析、路由与结果归并。
- 分布式事务:一个业务操作可能涉及更新多个分片的数据,如何保证跨库事务的ACID特性?常用方案有基于XA协议的二阶段提交、最终一致性方案(如TCC、Saga、本地消息表)等。
- 全局唯一ID:在单库中,自增主键简单有效。但在分布式环境下,需要能生成全局唯一、趋势递增且高性能的ID方案,如Snowflake算法、Leaf等。
- 跨分片查询:
JOIN操作、ORDER BY ... LIMIT、全表聚合统计等变得异常困难。通常需要业务上避免跨分片JOIN,或通过中间件进行数据聚合(性能损耗大),更优解是将数据同步到适合分析的OLAP系统(如数仓、ClickHouse)中进行。 - 数据迁移与扩容:当分片规则需要调整或数据分布不均时,如何平滑地进行数据迁移和集群扩容,保证业务不停机?这需要精密的工具和方案设计。
- 运维复杂度:监控、备份、故障恢复的对象从单个实例变为一个集群,运维难度和成本显著增加。
四、 架构实践与建议
- 评估与规划先行:不要过度设计。在单库性能出现明确瓶颈或可预见的增长前,优先考虑优化SQL、索引、缓存、读写分离等。当确需分片时,根据业务特点(查询模式、增长维度)精心设计分片键(如
user<em>id,order</em>id)和规则。 - 选择合适的中间件或框架:根据团队技术栈和掌控能力,选择成熟的、社区活跃的中间件,并充分理解其原理和限制。云服务商提供的分布式数据库(如PolarDB、TDSQL、Aurora)也提供了内置的透明分片能力,可降低自研复杂度。
- 业务代码适配:尽管中间件力图透明,但业务代码仍需做出一定调整,例如避免非分片键的频繁查询、重构复杂的关联查询逻辑、处理分布式事务等。提倡“数据库下沉,业务上浮”的架构思想。
- 构建数据生态:将分库分表的OLTP数据库定位为在线事务处理的核心,同时通过CDC(变更数据捕获)工具将数据实时同步到统一的OLAP数据平台,用于复杂查询、报表和分析,形成HTAP(混合事务/分析处理)架构。
- 重视监控与治理:建立完善的分布式数据库监控体系,涵盖连接数、慢查询、分片负载、数据分布均衡性等关键指标。制定数据生命周期管理策略,对历史冷数据进行归档。
五、
分库分表是业务高速发展背景下,数据处理与存储服务架构演进的必经之路。它通过将集中式的数据存储转变为分布式架构,解决了扩展性、性能和高可用的核心问题,但也带来了显著的复杂度。成功的分库分表实践,绝非简单的技术选型,而是需要结合业务远景、技术储备和运维能力进行通盘考虑的体系化工程。其最终目标,是为持续增长的业务构建一个既坚实可靠,又具备弹性伸缩能力的数据基石。
最新产品
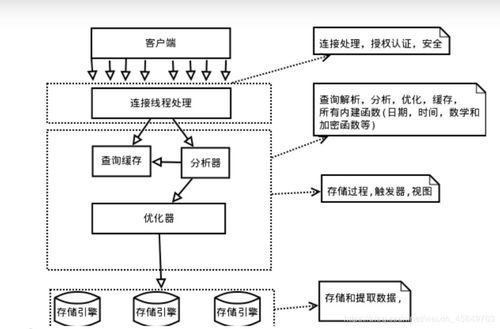
MySQL数据库 核心特点、架构解析与Linux环境实践
ERP的未来架构 数据处理与存储服务的革命性演进
Druid 大数据实时统计分析与数据处理存储服务
Calypso Systems推出测试软件与服务器,加速傲腾数据中心级持久内存数据处理与存储服务发展
大数据存储与处理 Hive与Pig的数据处理与存储服务探析
MySQL高级系列之一 深入解析数据处理与存储服务
面试笔记系列六 Redis、Kafka、Zookeeper与MongoDB核心梳理及对比
从原理到实践 互联网大厂的分布式事务解决方案全解析
Oracle RAC上云实战指南 数据处理与存储服务的高效迁移与部署
数据分析技术先行 如何提升数据处理与存储服务中的准确性