鹅厂发布超强算力集群,4天训练万亿大模型背后的数据处理与存储革新
腾讯云(“鹅厂”)发布新一代高性能计算集群,宣称可实现最快仅用4天完成万亿参数大模型的完整训练。这一突破性进展,不仅刷新了AI大模型训练的效率纪录,更将业界目光引向了其背后强大而复杂的数据处理与存储服务体系——这正是支撑如此庞大算力得以高效释放的基石。
算力集群:速度背后的硬件突破
此次发布的算力集群,其核心在于极致的硬件协同与网络优化。它集成了海量最新一代的GPU(如图形处理器),并通过自研的高性能网络互联技术,将成千上万的芯片紧密连接,形成一个具有超强浮点运算能力和极低通信延迟的“超级大脑”。正是这种近乎线性的扩展能力,使得万亿参数模型的海量矩阵运算得以被拆解并并行处理,从而将原本可能需要数月的训练周期压缩至以“天”为计。
数据处理的“高速通道”:吞吐与实时清洗
再强大的算力若没有充足、高质量的数据“喂食”,也会陷入空转。万亿参数模型的训练,意味着需要吞吐和处理PB(拍字节)乃至EB(艾字节)级别的原始数据。鹅厂的解决方案是构建了一条从数据源到计算单元的“高速通道”。
- 超高吞吐数据流水线:通过自研的数据预处理框架和调度系统,能够对海量文本、图像等多模态数据进行并行化读取、解码与初步格式化,确保数据能源源不断地、以接近网络带宽极限的速度输送给计算集群,避免算力“饥饿”。
- 实时数据清洗与增强:数据质量直接决定模型智商的上限。集群集成了智能化的数据清洗与标注平台,能在数据流入的利用规则引擎和预训练模型进行自动去重、纠错、过滤低质内容,并可实时进行数据增强(如文本改写、图像变换),动态扩充高质量训练样本,保障模型“学得好”。
存储服务的“海量仓库”:兼具容量、速度与可靠性
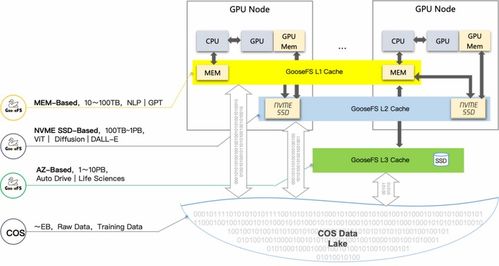
支撑这一过程的,是一套重新定义规模的存储服务体系。训练万亿模型,需要存储完整的训练数据集、数十万次的模型检查点、中间状态以及最终生成的庞大模型文件。
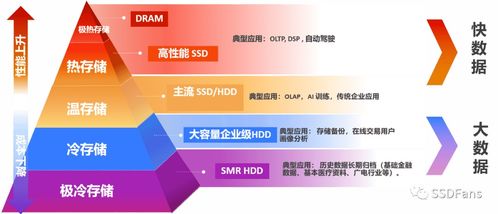
- 分级存储架构:采用“热-温-冷”分级存储策略。高性能分布式文件系统作为“热存储”,承载需要被计算节点频繁访问的当前训练数据和最新检查点,提供超低延迟的IO(输入/输出)性能。对象存储作为可靠且经济的“温-冷存储”,用于归档历史数据、备份模型版本,实现成本与效率的最优平衡。
- 检查点存储优化:模型训练中的“检查点”保存至关重要,它能在中断后快速恢复,避免巨大算力浪费。该集群的存储系统针对性地优化了大文件(单个检查点可达TB级)的快速写入与读取能力,将保存/恢复时间缩短了数倍,进一步提升了整体训练效率。
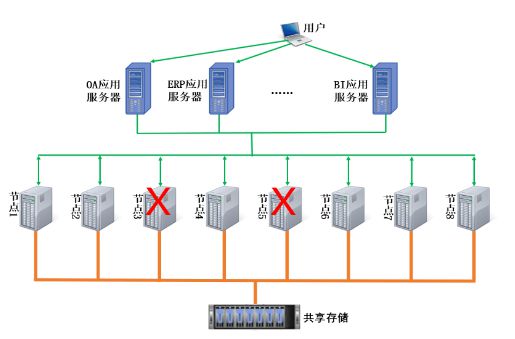
- 极致可靠与全球同步:通过多副本、纠删码等技术,确保每一份数据的安全。存储服务与全球数据中心网络打通,支持训练数据与模型资产的全球快速同步与分发,为跨地域协同研发和模型部署铺平道路。
软硬一体化的协同创新
鹅厂此次的突破,绝非单纯的硬件堆砌。其核心在于 “软硬一体化”的深度协同创新:从芯片互联、服务器架构,到操作系统、调度器、深度学习框架,再到上层的数据处理平台和存储服务,全部进行了垂直整合与优化。例如,其自研的机器学习框架与底层计算库深度适配,能最大限度发挥硬件算力;存储系统与计算框架直连,减少了数据移动开销。这种全栈优化,使得整个系统像一台精密的机器,每个环节都高效咬合,共同成就了“4天训练万亿模型”的奇迹。
对未来AI产业的深远影响
这一算力集群及其数据服务的发布,标志着AI大模型研发正式进入“工业化量产”时代。它极大地降低了超大模型研发的时间与成本门槛,使得更多机构能够投身于前沿探索。更重要的是,它将推动整个行业的基础设施标准,数据处理的速度、质量和存储的智能化管理将成为未来AI核心竞争力的关键组成部分。从赋能内部业务到通过腾讯云服务千行百业,这一强大的基础设施无疑将加速通用人工智能(AGI)的探索进程,并催生更多此前难以想象的大规模AI应用落地。
总而言之,鹅厂发布的不仅仅是一个算力集群,更是一套面向下一代AI的、覆盖数据处理、存储到计算的全栈基础设施解决方案。它揭示了一个核心趋势:在AI迈向万亿参数乃至更大规模的时代,决胜的关键将越来越依赖于将庞大算力、海量数据与智能存储无缝融合的“系统级能力”。
最新产品