数据分析中常见的存储方式与数据处理服务全景解析
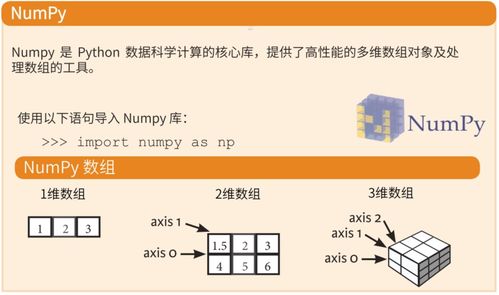
在当今数据驱动的时代,数据分析的效率和深度在很大程度上取决于底层的数据存储方式以及配套的数据处理与存储服务。合理选择存储方案和服务,不仅影响数据读写性能、成本,更直接关系到分析结果的实时性、准确性与业务价值。本文将系统梳理数据分析中常见的存储方式,并介绍主流的数据处理和存储服务。
一、 数据分析中常见的存储方式
数据分析的存储需求通常围绕大规模、高并发、多格式、实时或近实时展开。根据数据的使用场景(如热数据、温数据、冷数据)和分析模式(如OLAP、即席查询、批处理),存储方式主要分为以下几类:
- 关系型数据库(RDBMS)
- 特点与适用场景:以表格形式存储结构化数据,支持ACID事务和复杂的SQL查询。适用于需要强一致性、频繁更新、关系模型清晰的场景,如核心业务交易数据分析、报表系统。
- 常见代表:MySQL, PostgreSQL, Oracle, SQL Server。
- 分析考量:在处理海量数据(TB/PB级)和高并发分析查询时,传统单机RDBMS可能遇到性能瓶颈,常通过分库分表、读写分离或采用分析型关系数据库(如AWS Aurora, Google Cloud Spanner)来优化。
- 数据仓库(Data Warehouse)
- 特点与适用场景:专门为在线分析处理(OLAP)设计,存储从各业务系统集成、清洗后的历史结构化数据。采用星型/雪花型模型,支持复杂聚合查询和多维分析,是商业智能(BI)的核心。
- 常见代表:传统如Teradata, IBM Db2;现代云原生如Amazon Redshift, Google BigQuery, Snowflake, Azure Synapse Analytics。
- 分析考量:强于处理结构化数据的批量分析,查询性能高,但数据加载通常有延迟(小时/天级),属于“T+1”分析。
- 数据湖(Data Lake)
- 特点与适用场景:以原生格式(如Parquet, ORC, Avro, JSON, 文本、图像、视频)存储海量原始数据,包括结构化、半结构化和非结构化数据。模式在读取时定义(Schema-on-Read),提供极高的灵活性。
- 常见代表:基于对象存储构建,如Amazon S3, Google Cloud Storage, Azure Blob Storage;或与表格式结合,如Apache Hudi, Delta Lake, Apache Iceberg。
- 分析考量:是机器学习和探索性数据分析的理想底座,支持批处理、流处理等多种计算引擎(如Spark, Flink, Presto)直接访问。但缺乏原生管理,可能沦为“数据沼泽”,需通过数据湖治理框架(如Lakehouse架构)进行管理。
- NoSQL数据库
- 键值存储(如Redis, DynamoDB):适用于高速读写、缓存、会话存储等场景,在分析中常用于存储中间结果或实时特征。
- 文档数据库(如MongoDB, Couchbase):存储JSON-like文档,适用于内容管理、用户画像等半结构化数据分析。
- 宽列存储(如Cassandra, HBase, Bigtable):适合存储超大规模稀疏表,时序数据、物联网数据分析和推荐系统常用。
- 图数据库(如Neo4j, Amazon Neptune):专门存储实体和关系,用于社交网络分析、欺诈检测、知识图谱等场景。
- 实时/时序数据库
- 特点与适用场景:针对时间序列数据(如监控指标、传感器数据、金融行情)优化,支持高吞吐写入和高效的时间范围查询、聚合。
- 常见代表:InfluxDB, TimescaleDB(基于PostgreSQL), OpenTSDB, Prometheus。
- 分析考量:是IoT、运维监控、实时业务指标分析的核心存储。
- 搜索与分析引擎
- 特点与适用场景:专为全文搜索和日志分析设计,支持近实时索引和复杂的聚合查询。
- 常见代表:Elasticsearch, OpenSearch。
- 分析考量:常用于日志分析、应用性能监控(APM)、安全信息与事件管理(SIEM)以及文本数据的快速检索与统计分析。
二、 主流的数据处理与存储服务
云服务商提供了全托管的数据处理与存储服务,极大降低了企业自建和维护数据基础设施的复杂度。
- 数据处理服务
- 批量处理服务:
- AWS EMR / Azure HDInsight / Google Dataproc:全托管的Hadoop、Spark集群服务,用于大规模数据清洗、转换和批处理作业。
- AWS Glue / Azure Data Factory / Google Cloud Dataflow:无服务器ETL/ELT服务,提供可视化或代码方式编排数据管道,进行数据抽取、转换和加载。
- 流处理服务:
- Amazon Kinesis / Azure Stream Analytics / Google Cloud Dataflow (Streaming):用于实时处理数据流,如点击流分析、实时仪表盘、异常检测。
- Apache Flink托管服务(如Ververica Platform, AWS Kinesis Data Analytics for Apache Flink)。
- 查询引擎服务:
- Amazon Athena / Google BigQuery / Azure Synapse Serverless SQL Pool:无服务器交互式查询服务,可直接对数据湖(如S3)中的数据进行标准SQL查询,实现湖仓查询一体化。
- 数据存储服务
- 集成式分析平台(湖仓一体):这是当前的主流趋势,模糊了数据湖与数据仓库的界限。
- Snowflake:独立的云数据平台,将存储、计算分离,支持结构化、半结构化数据,兼具数据仓库的强大性能与数据湖的灵活性。
- Databricks Lakehouse Platform:基于Delta Lake等开放格式,在数据湖之上构建数据仓库的能力,统一了数据工程、数据科学和商业智能。
- Google BigQuery:本质上是Serverless的企业数据仓库,但通过BigLake引擎可直接分析存储在GCS(数据湖)中的多种格式数据。
- Amazon Redshift Spectrum / Azure Synapse Link:允许数据仓库直接查询外部数据湖中的数据,实现湖仓联动。
- 全托管数据库服务:各大云厂商均提供前述各种数据库的全托管版本(如Amazon RDS, Azure SQL Database, Google Cloud SQL for关系型;Amazon DocumentDB, Azure Cosmos DB for NoSQL),让用户专注于数据模型和应用,而非运维。
三、 选择策略与
选择合适的数据存储方式和服务,需要综合评估以下因素:
- 数据特性:结构、体积、速度(生成频率)、多样性。
- 分析需求:延迟要求(实时、近实时、批处理)、查询模式(点查、聚合、扫描、关联)、并发度。
- 成本:存储成本、计算成本、运维人力成本。
- 生态系统与集成:现有技术栈、团队技能、与上下游工具的兼容性。
- 未来发展:架构的弹性、可扩展性和演进能力。
现代数据分析架构往往是多种存储方式与服务的混合组合。一个典型的架构可能包括:
- 业务数据库(RDBMS)作为源头。
- 通过CDC或ETL工具将数据实时/批量同步到数据湖(对象存储)作为原始数据层。
- 在数据湖中利用Delta/Iceberg/Hudi等格式构建增量处理层和聚合层。
- 通过数据仓库(如BigQuery, Redshift)或直接使用Presto/Spark on Lakehouse为BI和即席查询提供服务。
- 将实时流处理结果写入键值库或文档库供在线应用调用。
- 利用搜索分析引擎处理日志和文本数据。
总而言之,数据分析的存储与处理格局正朝着云原生、存算分离、湖仓一体、实时智能的方向快速发展。理解各类存储方式的特性和丰富的云服务选项,是构建高效、灵活、低成本数据分析体系的关键第一步。
最新产品
数据分析中常见的存储方式与数据处理服务全景解析
十年大厂产品数据分析宝典(下) 从数据打点、图表分析到存储服务的实战技巧
C4模型 软件架构图中的艺术品,聚焦数据处理与存储服务
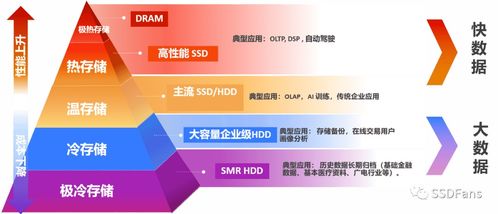
西部数据分层存储架构 以智能策略实现数据处理与存储的最佳效果
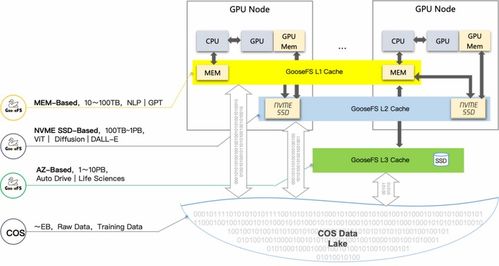
鹅厂发布超强算力集群,4天训练万亿大模型背后的数据处理与存储革新
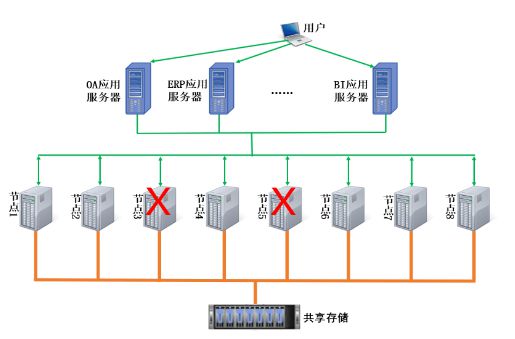
优炫软件在DTCC发布共享存储多写多读集群数据库,引领数据处理与存储服务新浪潮
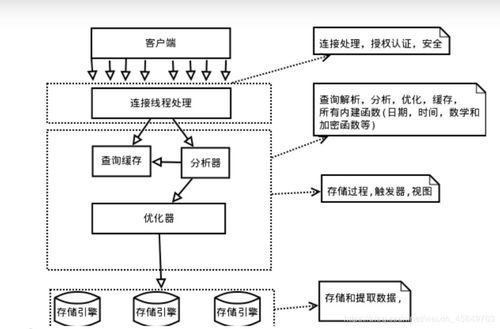
MySQL数据库 核心特点、架构解析与Linux环境实践
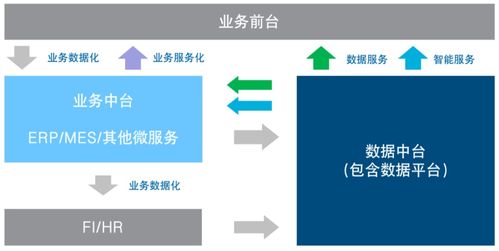
ERP的未来架构 数据处理与存储服务的革命性演进
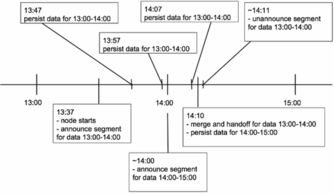
Druid 大数据实时统计分析与数据处理存储服务
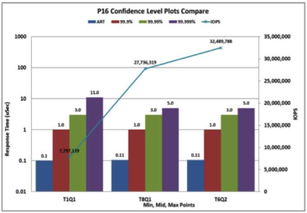
Calypso Systems推出测试软件与服务器,加速傲腾数据中心级持久内存数据处理与存储服务发展